Ulike typer uttrekk
Det finnes standardiserte metoder for å ta et uttrekk. Hvilken type man skal velge, avhenger av hva slags data man har og hvilket system disse er skapt i.
Primært kan systemene deles inn i to hovedgrupper: Noark-systemer og fagsystemer.
Noark-systemene følger kravene i Noark-standarden, en norsk standard for metadata i elektronisk arkiv og uttrekksformat for avlevering.
Begrepet fagsystem brukes om databaser, dataregistre og elektroniske system som ikke er godkjent etter Noark-standarden. Fagsystemer er utviklet for å støtte spesifikke arbeidsprosesser og oppgaver innenfor ulike fagområder. Det er en stor variasjon i hvor komplekse fagsystemene er og hvor enkelt det er å lage et uttrekk fra dem. Det er derfor viktig å legge en plan for hvordan man skal hente ut bevaringsverdig data og dokumentasjon til et strukturert og systemuavhengig format.
I denne veilederen har vi beskrevet de mest brukte uttrekkstypene og hva slags data de egner seg til. Hvis dere er usikre på hvilken hovedgruppe deres system faller under, ta gjerne kontakt med Nasjonalarkivet for veiledning.
Noark-uttrekk
Uttrekk fra Noark 5-systemer
Noark 5 er en standard for dokumentasjonsforvaltning og arkivdanning. Den stiller krav til arkivstruktur, metadata og funksjonalitet. Standarden angir hva et uttrekk skal inneholde, hvordan uttrekket skal være organisert og hvilket format dataene skal være i. I et Noark-uttrekk er arkivets logiske oppbygging beskrevet fra øverste nivå og ned til dokumentfil.
Alle systemer som er godkjent i henhold til Noark 5-standarden har funksjonalitet for å ta uttrekk etter fastsatte krav. Arkivskaper skal i utgangspunktet selv kunne bruke uttrekksfunksjonaliteten i et Noark 5-godkjent system.
Arkivforskriften § 28 sier at dersom et statlig organ skal avlevere dokumentasjon som er skapt i et informasjonssystem som er utformet i tråd med Noark 5, skal organet følge retningslinjene i Noark 5 for å produsere uttrekk. Dersom særlige grunner taler for det kan organet inngå avtale om å bruke andre metoder.
Uttrekk fra Noark 4-systemer
Et arkivuttrekk bør generelt tas fra det systemet og den versjonen dataene ble lagret i, da det reduserer risiko for feil. Dersom periodiseringen skjer i en Noark 4-løsning, bør deponeringen overføres til Nasjonalarkivet i Noark 4-format. Dersom Noark 4-løsningen er konvertert til en Noark 5-løsning før periodisering, kan deponeringen overføres til Nasjonalarkivet i Noark 5-format.
Tidligere versjoner av Noark
For versjoner med Noark 4 og bakover er det åpnet for at organet kan ta enten Noark-uttrekk eller SIARD-uttrekk. Et SIARD-uttrekk vil inneholde samtlige opplysninger fra utvalgte tabeller i en database. Slike uttrekk krever en detaljert systembeskrivelse som skal følge med ved deponeringen. Det skal avtales med Nasjonalarkivet hvilket uttrekk man leverer.
Tabelluttrekk
Tabelluttrekk innebærer å ta uttrekk fra en eller flere tabeller fra databasen bak et system.
For mange fagsystemer er det passende å speile tabeller i databasen som rene tekstfiler. Det inkluderer tekstfiler på fastlengde eller tegnseparert format (for eksempel CSV) og strukturerte filer på rene tekstformat som JSON eller XML. Siden databasehåndteringssystemer ofte er lisensiert programvare og lagrer data på ulike måter, har Nasjonalarkivet behov for å standardisere uttrekksformater.
Det er mulig å lage uttrekk som inneholder et utvalg av tabellene i databasen, eller en fullstendig kopi av databasen. Hva som er hensiktsmessig, må vurderes ut fra bevarings- og kassasjonsvedtaket. Skal man lage en ny sammenstilling av data, må det skrives spørringer for akkurat dette formålet. Da er det viktig å kjenne datamodellen godt. Jo flere tabeller som bevares, desto mer grundig systemdokumentasjon trengs for at dataene skal være anvendbare.
Kompleksiteten kan være høy og dataene må senere sammenstilles for å være forståelige. Videre kan det følge med opplysninger som ikke har langvarig dokumentasjonsverdi og skal slettes ut fra for eksempel personvernhensyn. Derfor er det viktig at Nasjonalarkivet mottar systemdokumentasjon sammen med uttrekket.
Tabelluttrekk gjøres enten direkte og beskrives med ADDML (se eget kapittel) eller med en SIARD-metodikk. Se riksarkivarens forskrift kapittel 5 del III om formatkrav m.m. ved uttak av databasetabeller.
Rapportuttrekk
Rapportuttrekk er en sammenstilling av data fra en database fremstilt som en avledet databasetabell eller et arkivdokument. For enkelte systemer er det naturlig å lage slike rapporter.
Rapportuttrekk kan være aktuelt for systemer som allerede har innebygd funksjonalitet for å lage rapporter til andre formål. Slik funksjonalitet vil ofte være utprøvd og kvalitetssikret og kan gi anvendbare og tilstrekkelige arkiv. Resultatet blir ofte en eller flere enkeltfiler med strukturerte data.
Hvis systemet verken har eksportmulighet eller forhåndsdefinerte rapporter, kan man diskutere med systemleverandør om det finnes alternative eksport-muligheter.
Rapportene som lages skal vurderes ut fra bevarings- og kassasjonsvedtaket. De skal være i et av dokumentformatene som er spesifisert i riksarkivarens forskrift § 5-17.
SIARD-uttrekk
SIARD (Software Independent Archiving of Relational Databases) er et format som er utviklet for bevaring av relasjonsdatabaser uavhengig av det opprinnelige systemet. En SIARD-fil inneholder en speiling av den underliggende databasen til et system, som én enkelt ZIP-fil med en samling av metadata og tabeller i XML-struktur. SIARD har relativt god verktøystøtte i produksjonen av uttrekk.
SIARD er ofte hensiktsmessig når all informasjon i et databasesystem skal bevares, men kan også benyttes for et utvalg av tabeller. SIARD-filen inneholder ikke nødvendigvis tilstrekkelig applikasjonslogikk og tabellrelasjoner for å være anvendbar i ettertiden. Derfor krever bruk av SIARD god systemdokumentasjon og kvalitetssikring av prosessen.
Mappestruktur-uttrekk
Mappestruktur er en hierarkisk organisering av mapper og filer i et datasystem. Har virksomheten for eksempel bygd opp et arkiv ved hjelp av filmapper og dokumentfiler på et delt nettverk, kan det være aktuelt å bevare strukturen og filsamlingen slik den ble skapt. Dette kan for eksempel være lyd-, bilde- og videomateriale.
Å bevare en mappestruktur kan være en aktuell uttrekksløsning i tilfeller der dokumentasjonen ikke ble skapt i etablerte arkivsystemer eller fagsystemer, men likevel anses som bevaringsverdig.
Denne uttrekksmetoden er mest vanlig for privatarkiv, men kan også være aktuell for enkelte typer arkivmateriale hos offentlige virksomheter.
Arkivdokumentene skal følge filformatkravene i riksarkivarens forskrift § 5-17, og det kan være nødvendig med filformatkonvertering før overføring til Nasjonalarkivet.
Uttrekk med mediekonvertert arkivmateriale
Skal dere konvertere deres avsluttede analoge arkiver og avlevere disse på et digitalt format, har Nasjonalarkivet utarbeidet to veiledere bør dere begynne med:
Det brukes samme type uttrekksformater for mediekonverterte arkiver som for digitalt skapt arkivmateriale.
Valget av uttrekksformat vil være avhengig av:
-
- om arkivet har tilhørende elektroniske metadata fra før eller om de må lages
-
- format og struktur på de elektroniske metadataene
-
- hvordan det fysiske arkivet er ordnet og organisert
Uavhengig av uttrekksformat må mediekonverterte arkiver ha en komplett teknisk struktur- og innholdsbeskrivelse i henhold til Nasjonalarkivets standard ADDML, som er beskrevet i denne veilederen.
Krav til dokumentasjon som skal leveres sammen med det mediekonverterte materialet finnes i riksarkivarens forskrift kapittel 8 – konvertering for digital bevaring.
Det skal fylles ut et eget skjema:
Skjemaet skal inngå i arkivversjonen.
Ta gjerne kontakt med oss på et tidlig tidspunkt for å avklare hvilket uttrekksformat som er best egnet for arkivmaterialet dere ønsker å mediekonvertere.
Tekniske detaljer om arkivuttrekk
For alle uttrekk skal det følge med en fullstendig teknisk struktur- og innholdsbeskrivelse i elektronisk form. Det vil si at det må lages en beskrivelse av de dataene som faktisk blir overført, og ikke bare av originalsystemet. Det viktigste er å lage en strukturert beskrivelse i et maskinlesbart format, fortrinnsvis XML, JSON eller tegnseparerte tekstfiler. Detaljerte krav til den tekniske dokumentasjonen finnes i riksarkivarens forskrift § 5-24 til § 5-26.
I dette kapittelet vil vi gå igjennom de ulike formene en slik beskrivelse kan ha, og presentere noen metoder som kan brukes i prosessen. Nasjonalarkivet tar langt på vei imot tekniske beskrivelser slik avgiver er i stand til å utforme dem, og er også behjelpelig med å omstrukturere dem i samarbeid med avgiver. Nasjonalarkivet kan også veilede om hvilken type dokumentasjon som er mest egnet for arkivversjonen som skal overføres.
Systemdokumentasjon
For at man i ettertid skal kunne forstå og bruke informasjonsinnholdet i uttrekket, trenger Nasjonalarkivet å motta relevant dokumentasjon om systemet. Samlet kaller vi dette systemdokumentasjon, som dekker både den tekniske dokumentasjonen, samt annen administrativ dokumentasjon som kan fortelle noe om hvordan systemet har blitt brukt.
-
- Visuell informasjonsmodell/datamodell
-
- Tabellbeskrivelser
-
- Kolonnebeskrivelser
-
- Spørringer og visninger fra databasen, slik som SELECT- eller VIEW-spørringer
-
- Skjema for arkivbeskrivelse
-
- Bevaringsvurdering(er)
-
- Saksbehandlingsrutiner
-
- Brukerveiledninger
-
- Systemmanual
-
- Skjermbilder fra systemet
-
- Kravspesifikasjoner
Systemdokumentasjonen legges i en egen mappe ved navn «sysdok» i arkivversjonen.
For Noark 5-uttrekk er kravene til systemdokumentasjonen mindre omfattende, da systemene allerede er godkjent etter Noark-standarden. Det er likevel ønskelig at sysdok-mappe følger med.
Filformater for arkivdokumenter
I tråd med ny arkivforskrift skal Nasjonalarkivet og arkivskaper avtale hvilke filformater som skal inngå i en arkivavlevering (arkivforskriften § 21 e.).
Hvilke filer som skal inngå i den enkelte avleveringen avhenger av hvordan arkivet er skapt, hvilke informasjon det inneholder, muligheter til å forstå innholdet og hva som kan sikre langtidsbevaring.
Verktøy
Nasjonalarkivet har utviklet verktøyet Arkade 5. Dette kan brukes til å generere metadata og identifisere filtyper, og skal senere benyttes for å pakke for overføring til Nasjonalarkivet. Arkade 5 tilbyr en PRONOM filformatanalyse. I tillegg til å identifisere filtypene, kontrolleres disse opp mot de godkjente filformatene for avlevering og deponering.
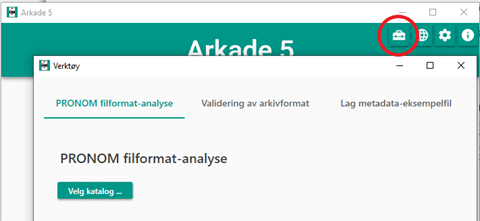
En PRONOM filformatanalyse er en identifisering av filformater mot det tekniske filformatregisteret PRONOM, som er utviklet av det britiske nasjonalarkivet. Filendelser gir ofte hint om et filformat, men er ikke tilstrekkelig for å vite hva filen faktisk inneholder. For eksempel finnes det mange versjoner av PDF, og hver versjon kan igjen grupperes ut fra ulike konformitetsnivåer. Hvert av disse vil ha en unik PUID for å identifisere filtypen. Filidentifisering gjenkjenner og klassifiserer filer, men utfører ikke en validering av om filen følger alle formatkrav. Arkade 5 tilbyr per i dag en innebygd funksjon for validering av PDF/A-formater. Det finnes mange ulike valideringsverktøy for ulike format.
Filformatanalysen vil avdekke hvilke filer som krever konvertering. Filformatkonverteringer varierer stort i kompleksitet, og siden det kan skje feil ved konverteringer kan man gjerne beholde produksjonsformatet og gjenskape strukturen i en egen mappe for de konvertere dokumentene. Disse to mappene kan for eksempel hete original og konvertert.
Når det gjelder selve konverteringen er det viktig å velge riktig verktøy. Det finnes en mengde konverteringsverktøy, og hvilket som er best egnet avhenger av filformatene som skal konverteres. Noen verktøy er spesialtilpasset for visse filformater, men andre er mer generelle.
For å sikre at alle filene er konvertert til egnede arkivformater, kan de konverterte filene kontrolleres på nytt med en PRONOM filformatanalyse. Dette vil bekrefte at filene har blitt konvertert til ønskelig arkivformat. For PDF-dokumenter anbefales det i tillegg å benytte valideringsverktøy som veraPDF, som kontrollerer at filene oppfyller alle kravene i PDF/A-standarden.
Uttrekk fra Noark-systemer
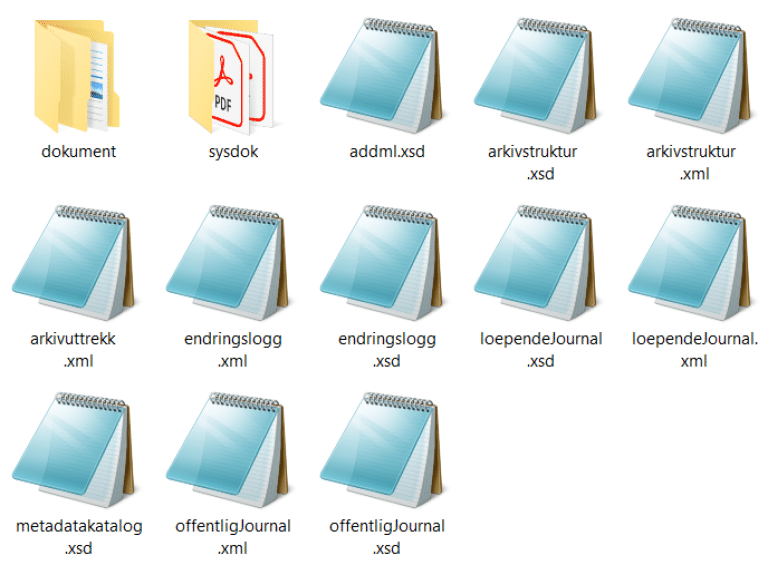
Uttrekket skal inneholde arkivdokumenter, journalrapporter, metadata og endringslogg for en arkivdel og avgrenset tidsperiode. Uttrekket vil bestå av en samling XML- og XSD-filer som følger strukturen definert i Noark 5-standarden, samt en tilhørende mappe kalt «dokumenter» med dokumentfiler.
Opprydding bør utføres ved hjelp av funksjonalitet i løsningen, der arkivleder for eksempel kan masseavslutte saker per arkivdel. Det er ikke ønskelig at brukere med administrasjonsrettigheter gjør endringer direkte i databasen. Slik praksis kan resultere i tap av informasjon og manglende logger, og autentisiteten vil da svekkes.
Et uttrekk skal omfatte en avsluttet arkivperiode, og bestå av innholdet i en eller flere avsluttede arkivdeler.
Det bør være mulig å ta et uttrekk på grunnlag av start- og sluttdato, uavhengig av tilhørighet til arkivdel og om mappene er avsluttet eller ikke. Fra enkelte fagsystemer kan det være aktuelt å ta uttrekk basert på start- og sluttdato, uten hensyn til om mappene er avsluttet eller hvilken arkivdel mappene tilhører. Aktuelt seleksjonskriterium kan da for eksempel være journaldato.
Det skal også dokumenteres hvilke integrasjoner som er gjort mot andre systemer, lokale tilpasninger for møtebehandling og virksomhetsspesifikke metadata.
Uttrekksfunksjonalitet er en forutsetning for Noark-godkjenning av systemleverandører, og blir demonstrert for Nasjonalarkivet i løpet av godkjenningsprosessen. Dette skal sørge for at avgiver selv kan ta uttrekk.
Avgiver kan også teste Noark-uttrekk opp mot standarden med
Arkivversjonen skal inneholde en fil med navn arkivuttrekk.xml som beskriver arkivuttrekket og filene i det. Den skal inneholde følgende informasjon om et Noark 5-uttrekk:
-
- Arkivskapernavn – Kan være flere enn én
-
- Navn på systemet/løsningen
-
- Navn på arkivet – Daglignavn på arkivet hos arkivskaper
-
- Start- og sluttdato
-
- Hvilken type periodisering som er utført i forrige periode og denne periode. Den som er ansvarlig for å ta uttrekket skal angi hva slags type periodisering som er foretatt – enten skarpt periodeskille eller mykt skille (med bruk av overlappingsperiode). Dette har betydning for innholdet i arkivuttrekket. En eventuell tidligere periodisering skal også dokumenteres.
-
- Om det finnes skjermet informasjon i uttrekket. Dersom arkivuttrekket inneholder skjermet informasjon, skal alle nødvendige metadata for skjerming også følge med i uttrekket.
-
- Om uttrekket omfatter dokumenter som er kassert
-
- Om uttrekket inneholder dokumenter som skal kasseres på et senere tidspunkt. En arkivversjon skal kun inneholde dokumentasjon som skal bevares for ettertiden. Ved overføring til Nasjonalarkivet skal kassabel dokumentasjon ikke følge med, men metadata for de kasserte dokumentene skal inngå.
-
- Opplysning om det finnes virksomhetsspesifikke metadata i arkivstruktur.xml
-
- Antall mapper i arkivstruktur.xml
-
- Antall registreringer i arkivstruktur.xml, loependeJournal.xml og offentligJournal.xml
-
- Antall dokumentfiler
-
- Sjekksummer for alle XML-filer og XML-skjemaer i uttrekket
Uttrekk fra databasen til et fagsystem
De fleste uttrekkene fra fagsystem som overføres til Nasjonalarkivet, overføres i form av en eller flere tabeller hentet fra systemets underliggende database. Disse tabellene er ofte i form av strukturerte tekstfiler. Eksempler på dette er XML, JSON, fastbredde eller tegnseparerte (for eksempel CSV).
Det finnes flere metoder for å trekke ut innholdet fra en database. Metodene varierer med ulike plattformer, nettverk og brukertilganger. For å finne den mest hensiktsmessige metoden for et bestemt system, må dere vurdere mulighetene som er tilgjengelige og samarbeide med de som drifter systemet.
De fleste databaseløsninger har eksportfunksjonalitet innebygget, som ofte likner på funksjonalitet for å importere datatabeller til databasen. Mange databaseløsninger har også liknende funksjonalitet i form av rapportfunksjoner.
En annen måte å gjøre uttrekk fra databaser på, er å foreta spesifikke SELECT-spørringer direkte i databaseløsninger og eksportere resultatet som en tekstfil. På den måten kan man slå sammen tabeller om dette er hensiktsmessig, med tanke på bevaringsvurderingen som er gjort for systemet.
Det finnes også ekstern programvare som kan lese data fra databaser, bearbeide og eksportere dem. Men også programmeringsspråk som Python og C# har pakker som kan brukes for å lese og eksportere data fra databaser. Et annet alternativ er kommandolinjeverktøy i operativsystemene, slik som SQLCMD.
I Microsoft SQL Server Management Studio (SMSS) kan man høyreklikke på databasen, velge “Tasks” og “Export data”. Man kan da velge hvilke tabeller man vil eksportere, og hvilket tekstfilformat man ønsker dataene i.
Uttrekk av mappestruktur
Produksjon av uttrekk
Start med å identifisere de mappene og dokumentfilene som skal bevares i henhold til bevarings- og kassasjonsplanen.
Mappestrukturen kan allerede ha en logisk struktur som er tilstrekkelig for betjening og gjenfinning og gi nyttig informasjon om hvordan arkivet ble skapt. Det kan i andre tilfeller være aktuelt å bare ta med et utvalg av mapper og dokumenter. Det som skal bevares, skal så kopieres til en ny plassering.
Filformat
Det skal så kontrolleres hvilke filformater arkivdokumentene har og sammenstille en beskrivelse av strukturen. En mappestruktur inneholder som regel dokumenter i produksjonsformat, som ofte ikke er egnet for langtidsbevaring. I så fall må disse konverteres til godkjent arkivformat.
Dokumentasjon av uttrekk
Det må til slutt lages en beskrivelse av mappestrukturen. Detaljeringsnivå kan her vil avhenge av formål og eksisterende navngiving på mapper og filer. Finnes det allerede registre, arkivkoder eller oversikter, skal man ta utgangspunkt i disse. Detaljeringsnivå avtales i samarbeid med Nasjonalarkivet.
Uttrekk i SIARD-format fra databaser
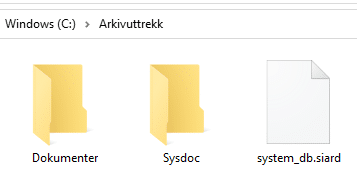
Uttrekket skal inneholde en eller flere SIARD-filer, en «sysdok»-mappe med systemdokumentasjon og en undermappe for eventuelle eksterne dokumentfiler fra arkivet.
Selve SIARD-filen inneholder data fra en relasjonsdatabase i en ZIP-fil med to undermapper, «header» og «content». Mappen «header» inneholder filen metadata.xml, som har de overordnede metadataene om hver tabell, slik som tabellnavn, kolonnenavn, primær- og fremmednøkler, datatyper og liknende. Mappen «content» inneholder informasjonen som er i hver enkelt datatabell, i form av en mappe for hver tabell med nummererte XML-filer for hver tabell, og eventuelle filer med innholdet til LOB-er som er lagret i tabellene.
Uttrekk i SIARD-format kan tas ved hjelp av ulike verktøy som har sine fordeler og ulemper. Nasjonalarkivet har kjennskap til tre programvarer som tar uttrekk i SIARD 2.1-format, hvorav en er lisensiert (Spectral Core Full Convert) og de to andre er fri programvare (Siard Suite og Database Preservation Toolkit). Sikker bruk og installasjon av programvaren må avgiver selv ta ansvaret for. Uavhengig av verktøy, er det viktig at denne konverteringsprosessen dokumenteres så mye som mulig og at alle mulige logger opprettes og tas med.
I utgangspunktet kan arkivskaperen selv trekke ut arkivdata fra sin database. Dette forutsetter at man har tilstrekkelig tilgang for SQL-tilkobling til ønsket database (plattform-, database- og bruker-spesifikk). Det vil ofte også være behov for å ha administratortilgang til egen lokal PC. Har man ikke nødvendige tilganger, må dette ordnes, eventuelt i samarbeid med en tjenesteleverandør.
Database Preservation Toolkit (dbptk) er et verktøy som kan brukes for å generere SIARD-filer ved å koble seg til en relasjonsdatabase
-
- Start dbptk og trykk «Create»
-
- Velg aktuell databaseformat
-
- Fyll ut tilkoblingsinformasjon for den aktuelle databasen og trykk «Test Connection»
-
- Dersom tilkoblingen virker, trykk «Next»
-
- Sjekk at tabeller er med i uttrekket og trykk «Next».Et bilde som inneholder tekst, himmel, kart
-
- Funksjonene med «Custom Views» og «Merkle Tree Filter» kan hoppes over ved å trykke «Skip».
-
- Velg mappe dit SIARD-filen skal eksporteres til.
-
- Alternativene om til komprimering, menneskelig-lesbare XML-er og lagring av LOB i eller utenfor SIARD-filen avtales med Nasjonalarkivet.
-
- Feltene med metadata i selve SIARD-filen er ikke obligatoriske, men legg gjerne inn beskrivende informasjon. Trykk «Create»
-
- SIARD-filen opprettes og denne legges på rotnivå i arkivpakken.
ADDML
ADDML (Archival Data Description Markup Language) er Nasjonalarkivets egenutviklede standard for teknisk beskrivelse av datasett. Standarden brukes for å beskrive poststrukturerte datafiler (tabelluttrekk) på teknisk detaljnivå. Standarden er i de senere år utvidet med muligheter for kontekstuell beskrivelse, men er fortsatt primært beregnet på teknisk beskrivelse.
En ADDML-fil skal inneholde både kontekst- og innholdsbeskrivelse. Filen skal også inneholde informasjon om hvor data finnes og hvordan dataene leses, forstås og etterprøves. Hvis det er gjort tilpasninger innen tegnsett eller kompliserte felter i løpet av uttrekksprosessen, vil ADDML-en være den maskinlesbare dokumentasjonen.
ADDML-filen skal inneholde referanseinformasjon om aktører og system som var med på å skape informasjonen i uttrekket.
-
- Aktører
-
- Rolle – Arkivskaper, Produsent [av uttrekket], Arkiveier
-
- Type – Individ, Organisasjon, System
-
- Kontaktperson
-
- Aktører
-
- System
-
- Systemtype – Noark 3-5 [implementert], Fagsystem eller annet fra listen lenger oppe.
-
- Navn – Daglig-navn på løsning hos arkivskaper
-
- Versjon – Versjonering av systemet
-
- System
ADDML-filen skal også inneholde informasjon knyttet spesifikt til uttrekket, som utvalgskriterier rundt start- og sluttdato for arkivskapning og typen uttrekk som blir overført.
-
- Arkivperiode
-
- Start- og sluttdato
-
- Periodeskille
-
- Arkivperiode
-
- Arkivuttrekk
-
- Dato for uttrekk
-
- Type uttrekk, trenger ikke være samme som system-typen
-
- Arkivuttrekk
-
- Liste opp filene med «registerdata», med filnavn, sjekksum og antall poster per fil.
-
- Så lager man definisjoner for alle nivåer; fil, post og felt.
-
- For felter som bruker kodet verdi, skal også kode med forklaring beskrives.
-
- Så lager man definisjoner for alle nivåer; fil, post og felt.
-
- Legg til nøkler per post-definisjon, både identifiserende / unik nøkkel og kobling til andre post-definisjoner / fremmednøkkel.
-
- Deretter knytter man fil, post og felt til en konkret måte for lesing av data, for eksempel tegnsettet i filen, post- og felt-skiller og om et felt inneholder en dato-verdi eller fødselsnummer.
-
- Til slutt legges det til prosesser, som etterprøver den øvrige dokumentasjonen i filen med hva som faktisk finnes i uttrekket; kontroller sjekksum, datatype, antall poster, osv.
For Noark 5 finnes kun referanse-informasjon og registerdata i ADDML, fordi beskrivelser, lese-informasjon og prosesser allerede er beskrevet andre steder, blant annet i standarden. Så ADDML-filen vil inneholde statistiske data om antallet poster, sjekksum og relasjon mellom filene (hvilke XML-filer som valideres med hvilke XSD-er). Hvis det er tatt i bruk andre elementer enn de som finnes beskrevet i standarden, skal disse beskrives med et eget XML-skjema.
Dere kan lage ADDML-beskrivelsen enten ved hjelp av Nasjonalarkivets eget verktøy, Arkadukt, eller i en tekst- eller XML-editor. En XML-editor med auto-complete vil kunne generere en ADDML-fil med minimal kunnskap om standarden, samtidig som man får fylt ut det meste av informasjon på en strukturert måte.
Arkadukt fås ved henvendelse til Nasjonalarkivet. Programmet krever Java SDK versjon 7u79 og er sist oppdatert i 2014. Hvis dette hindrer dere i å ta i bruk programvaren, spør Nasjonalarkivet om konkrete eksempelfiler eller teknisk veiledning. Programmet gjør det lettere å lage en ADDML-fil, ved å legge et grafisk grensesnitt over syntaksen i filen, og legger opp til utfylling av faste felter i stedet. Underveis i arbeidet vil programmet rapportere om eventuelle mangler i filen, så man kan se om noe er feilsitert eller gjenstår.
Kontakt oss
Ta gjerne kontakt med Nasjonalarkivet om du skulle ha spørsmål eller trenger ytterlige veiledning. Det finnes blant annet muligheter for å overføre et prøveuttrekk for få tilbakemeldinger.
Vi vil også gjerne komme i kontakt for å lære om utfordringer og metoder for å gjennomføre uttrekk.
Skriv til oss på postmottak@arkivverket.no, så kan vi sette opp et digitalt møte.